RL Framework Worklog I -- Handling Off-policy
Training large language models with reinforcement learning runs into a fundamental issue: off-policiness. As the policy updates, the rollouts still arriving from earlier checkpoints become stale—their distribution drifts away from the current model. In latency-heavy, agentic/tool-calling settings (web calls, DB queries, GUI actions), rollouts can take minutes, so staleness is the norm, not the edge case.
In our experiments, we found a sharp asymmetry: positive-reward data tolerates staleness surprisingly well, but negative-reward data collapses under moderate off-policiness. We then show a simple, effective fix: asymmetric importance ratio clipping, which stabilizes training for stale negatives while preserving sample-efficiency on positives.
What is Off-Policiness?
Off-policiness measures the divergence between the policy that generated training data and the current policy being optimized. Let $\pi_{\text{old}}$ be the policy that generated trajectory $\tau$, and $\pi_\theta$ be the current policy. The importance ratio at trajectory level is:
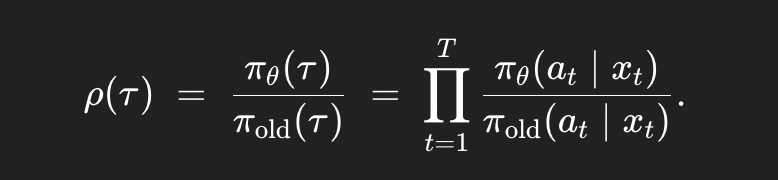
As training progresses, trajectories sampled from $\pi_\text{old}$ become increasingly unrepresentative of $\pi_\theta$'s behavior. When $\rho \gg 1$ or $\rho \ll 1$, gradient estimates become high-variance and potentially destructive to model performance.
Why Off-Policiness Hurts GRPO/PPO Training
The policy gradient with importance sampling in GRPO/PPO takes the form:
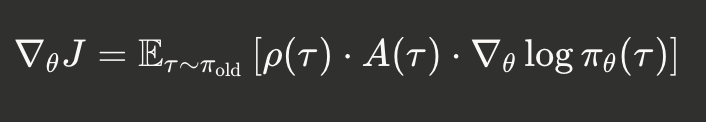
where $A(\tau)$ is the advantage (calculated via GAE over learned value function in PPO or group normalization in GRPO). Separating by advantage sign reveals the core asymmetry:
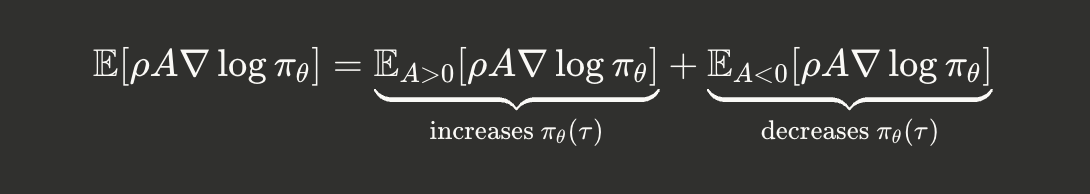
The critical insight:
- For positives $(A > 0)$ : The gradient increases $\log \pi_\theta(\tau)$ , pulling the policy toward these trajectories
- For negatives $(A < 0)$ : The gradient decreases $\log \pi_\theta(\tau)$, pushing $\pi_\theta(\tau) \rightarrow 0$
The negative term creates an unbounded optimization problem: we can always decrease the loss further by driving $\pi_\theta(\tau)$ toward zero for any negative trajectory from $\pi_{\text{old}}$. Under stale data, this becomes catastrophic—the model wastes capacity "digging holes" in probability space where it no longer explores, potentially erasing useful features.
Baselines help variance but do not remove this sign asymmetry. the effect survives GRPO, PPO, and vanilla REINFORCE forms.
In-Flight Weight Updates: Embracing Staleness
Rather than waiting for all rollouts to complete before updating, in-flight weight updates continuously update the policy while rollouts are still being generated. This approach, detailed in Magistral (arxiv:2506.10910) and related work (arxiv:2505.24298, arxiv:2509.19128), addresses long-tail latency by:
- Updating the policy asynchronously without blocking on slow rollouts
- Either recomputing KV cache or continuing from stale KV cache when weights update mid-generation
- Using importance weighting to correct for the resulting staleness (V-Trace – used by both Areal and LlamaRL to mitigate off-policiness)
This is crucial for real-world agentic systems where tool calls (database queries, API requests, GUI agents) have unpredictable latency.
Experiments: Negative Rewards and Off-Policiness
We trained Qwen3-30B-A3B on MATH500 (a standard mathematical reasoning benchmark) to quantify how negative rewards degrade under off-policy conditions. Training was conducted using the Slime Framework on 8× H100 GPUs with a global batch size of 256.
Our setup uses two inference servers:
- Current server: Always uses the latest policy checkpoint
- Stale server: Uses the policy from $k$ gradient steps ago (i.e., on-policy for the first $k$ steps of training, then perpetually stale by $k$ steps thereafter)
Unlike standard off-policy training where all data comes from a single stale policy, we isolate staleness effects by reward type:
For each prompt, we generate responses from:
- π(t): Current policy checkpoint
- π(t-k): Policy from k gradient steps ago We then create hybrid datasets:
- Stale Positive: Positive-reward trajectories from π(t-k), negative from π(t)
- Stale Negative: Negative-reward trajectories from π(t-k), positive from π(t)
This lets us measure staleness impact on each reward type independently, unlike standard off-policy setups where all rewards degrade together.
We measure maximum reward (accuracy) achieved over 30 training steps.
Results: Max Reward Achieved on MATH500
| Training Setup | Stale Positive Rewards | Stale Negative Rewards |
|---|---|---|
| On-policy (0 stale) | 0.73 | 0.72 |
| 3-gen stale | 0.76 | 0.48 |
| 5-gen stale | 0.78 | 0.18 ⚠️ |
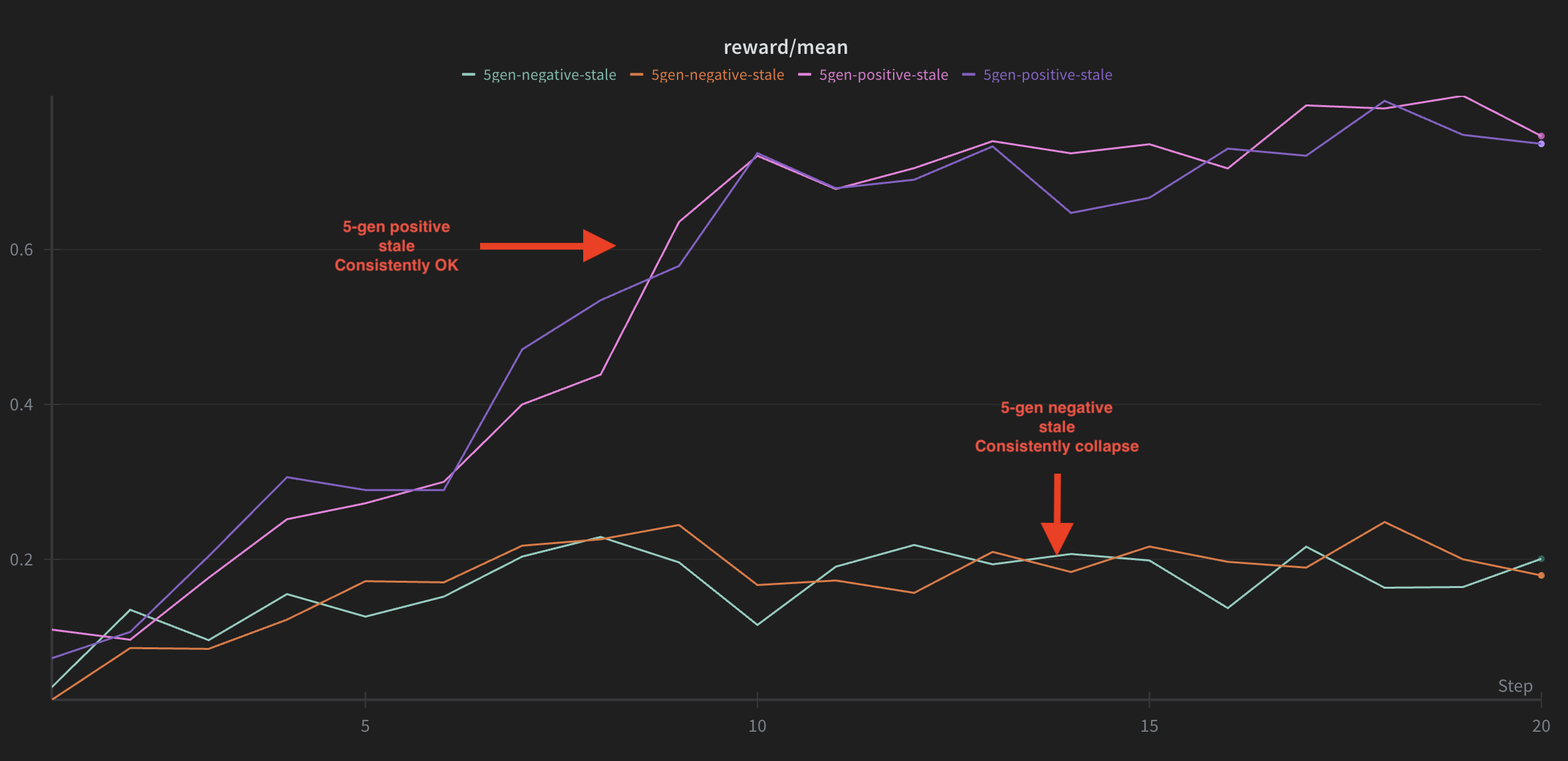
Key findings:
- With positive rewards, staleness has minimal impact—performance even improves slightly (0.73 → 0.78)
- With negative rewards, training catastrophically collapses at 5 steps of staleness (0.72 → 0.18, a 75% drop)
- The model never recovers from this collapse, getting stuck in a destructive loop
This asymmetry occurs because negative gradients actively push probabilities toward zero. When the data is stale, the model has already shifted away from these trajectories—the negative gradient then destroys representations that might now support positive behaviors.
Asymmetric Importance Clipping
V-trace from IMPALA (https://arxiv.org/abs/1802.01561) addresses off-policiness through importance ratio clipping:
$$\bar{\rho} = \min(\rho_\text{max}, \rho(\tau))$$
However, this treats positive and negative rewards symmetrically. We propose asymmetric clipping that respects the differential fragility:
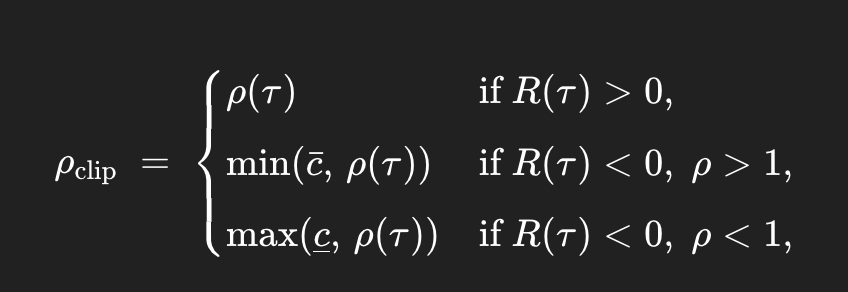
where $\bar{c} = 1.0$ (no upweighting) and $\underline{c} = 0.5$ (gentle downweighting).
Rationale:The asymmetric clipping provides different treatment based on reward sign and staleness:
- Positive rewards + high $\rho$ : Allow upweighting (up to $c_{\text{pos}}$ ) for faster learning
- Positive rewards + low $\rho$: Natural downweighting is fine, still learning the right direction
- Negative rewards + high $\rho$: Cap at 1.0 to prevent amplifying negatives the model now prefers
- Negative rewards + low $\rho$: Floor at 0.5 to maintain signal without destructive "dig a hole" behavior
Pseudo-code
def asymmetric_clip(rho, advantage, c_pos=10.0, c_neg_up=1.0, c_neg_down=0.5):
"""
Asymmetric importance ratio clipping based on advantage sign.
Args:
rho: Importance ratio π_θ(τ) / π_old(τ)
advantage: GRPO normalized advantage (can be ±)
c_pos: Maximum ratio for positive advantages
c_neg_up: Maximum ratio for negative advantages when ρ > 1
c_neg_down: Minimum ratio for negative advantages when ρ ≤ 1
"""
if advantage > 0:
# Positive: allow upweighting for acceleration
return torch.clamp(rho, max=c_pos)
else:
# Negative: prevent destructive updates
if rho > 1.0:
# Don't amplify negatives we now prefer
return torch.clamp(rho, max=c_neg_up)
else:
# Maintain minimum gradient signal
return torch.clamp(rho, min=c_neg_down)
# In GRPO training loop
importance_ratio = (pi_theta_logprobs - pi_old_logprobs).exp()
clipped_ratio = asymmetric_clip(importance_ratio, advantage)
loss = -(clipped_ratio * advantage * pi_theta_logprobs).mean()
Why this works?
The asymmetric approach addresses the core failure mode of off-policy training with negatives:
- Prevents unbounded optimization: By capping negative importance weights at 1.0, we prevent the model from aggressively pushing away from trajectories it has grown to like
- Maintains learning signal: The floor at 0.5 for stale negatives ensures gradients don't vanish entirely
- Accelerates positive learning: High caps for positives allow the model to quickly exploit good trajectories even when off-policy
- No KL penalty needed: This approach achieves stability without the computational overhead of KL regularization
Future Directions
- Dynamic Clipping Schedules
Rather than fixed thresholds, adaptively scale clipping based on observed staleness:
# Track staleness impact
staleness_metric = compute_kl(pi_current, pi_old)
c_neg_down = max(0.1, 0.5 * exp(-staleness_metric))
c_pos = min(20.0, 10.0 * (1 + staleness_metric))Conclusion
Off-policiness is not merely a theoretical concern—it manifests as catastrophic performance degradation, particularly for negative rewards in long-tail rollout scenarios. Our experiments clearly demonstrate an asymmetry: positive rewards tolerate and even benefit from staleness, while negative rewards collapse dramatically.
Asymmetric importance clipping provides a simple, effective solution that:
- Stabilizes training under high off-policiness
- Maintains sample efficiency
- Requires no KL regularization
- Integrates seamlessly with existing GRPO pipelines
For real-world agentic RL with unpredictable tool-calling latencies, this technique is essential for stable, scalable training.