Plural Minds: Exploration-First Inference for LLMs
An experiment on improving LLM output diversity

Most people have seen this duck-rabbit illusion. Do you see a duck? A rabbit? Try to see both simultaneously—you can't, but you know both are there. Your brain maintains both interpretations, flipping between them based on subtle attentional shifts.
I've been reading Gwern's blog about LLM creativity and it got me thinking: why can't our models do this?
The Expectation-Reality Slider
Every perception blends expectation with observation:
Output = α · Expectation + (1-α) · Observation \
where α = f(uncertainty, task, context)
This isn’t a metaphor—it’s literally how perception works. The brain doesn’t “see”; it infers. Top-down predictions meet bottom-up sensory signals and the balance shifts with signal quality. When inputs are ambiguous or sparse, priors dominate (high α)—think of the intensified prior-driven perception reported under psychedelics. When the evidence is strong, observations dominate (low α). In that sense, the brain is always hallucinating—most of the time usefully—by bending raw data toward expectations, then correcting when errors push back. Here's a cool video showing this in action.
The key: when prediction errors persist, we don't just suppress them—we explore. That's where discovery happens.
Why LLMs Collapse Too Soon
Pretraining (MLE) is mode-covering: learn a broad distribution that assigns mass to many legitimate alternatives.
Post-training becomes mode-seeking via three contractions:
- Alignment (RLHF/Constitutional): shifts mass toward predictable, safe outputs.
- Verification (RLVR): zeros out unverifiable regions.
- Inference heuristics (greedy/low-T): skim only the peak.
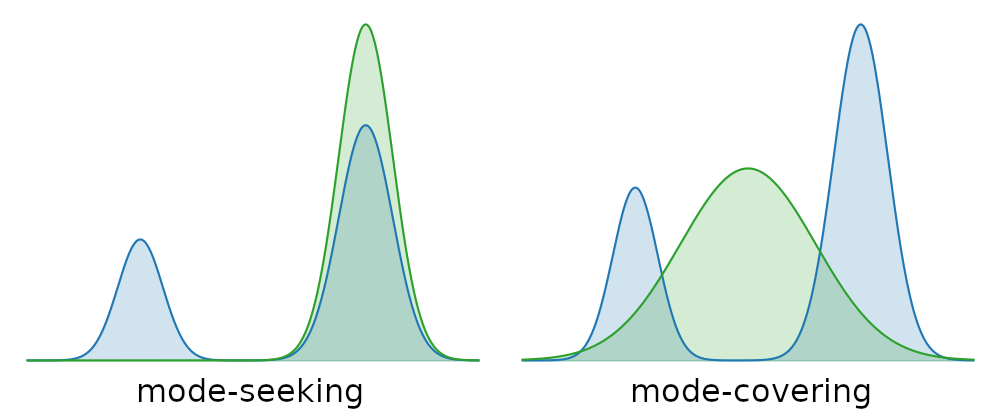
Essentially, pretraining builds the space. Post-training prunes it. Decoding then commits to a single ridge line.
The Core Problem: Temporal Commitment
None of that would be fatal if the model could still walk more than one path through its learned space during generation. During decoding, once token N is emitted, the system has implicitly committed to an interpretation for token N+1. Even if the tail of the distribution still contains viable alternatives, the single trajectory has to double-down. This is the temporal commitment problem: not that the model lacks multiple hypotheses, but that it can’t keep them alive through time, delay commitment until late evidence lands, or revise earlier choices when downstream tokens contradict them.
However, the way humans think is different. We carry competing hypotheses—face… maybe abstract… still either… okay, with this detail it’s a face—and let new evidence flip us. In brains, this looks like predictive coding plus prospective replay: top-down predictions meet bottom-up errors, and internally generated sequences scout alternative futures before committing an action or an interpretation. Hippocampal work on model-based planning shows precisely this ability to maintain and evaluate multiple candidate paths over time, then settle only when the evidence and goal structure force it.
# Current LLM inference
def generate_token(context):
distribution = model(context) # Rich distribution
token = sample(distribution) # Irreversible collapse
return token # No backtracking
# Human-like maintenance
def maintain_hypotheses(context):
hypotheses = get_active_hypotheses()
for h in hypotheses:
h.weight *= likelihood(context | h)
# Delay commitment until overwhelming evidence
if max(weights) > 0.95:
return collapse_to_best()
return maintain_superposition()Figure 4: Pseudo-code of how LLM think and how humans think.
Exploration as Hypothesis Testing
The temporal commitment problem reveals a deeper issue: we've trained models to treat anomalies as errors rather than information. In biological systems, exploration isn't random wandering—it's active hypothesis testing precisely where the model is most uncertain.
Consider how scientific discovery actually works: you maintain a strong theory, encounter an anomaly that violates it, and—crucially—you don't immediately discard the anomaly. You explore its neighborhood, testing whether it reveals something your theory missed. We've optimized step one (strong priors) into LLMs, but trained out their capacity for the rest. Without the ability to protect alternate hypotheses, they can't explore violations or revise theories.
The Verification Trap
This connects directly to what I call the verification trap, crystallized in approaches like RLVR (Reinforcement Learning from Verifiable Rewards). The principle sounds reasonable: only reward outputs you can verify. But verification criteria lag innovation by definition. The Wright brothers' machine couldn't be verified as flight-capable until December 17, 1903, when it actually flew. Before that moment, every metric—lift calculations, wind tunnel data—was a provisional proxy.
New criteria often arrive after success—verification lags invention.
— From a wise man (me???)

When we restrict rewards to the verifiable, we create a vicious cycle:
- Novel outputs can't be verified (no criteria exist yet)
- No verification means no reward
- No reward trains the model to avoid novelty
- The system converges on "verified-safe" outputs
We're asking models to discover new territories while only rewarding them for staying on marked paths.
The Two-Phase Solution: Explore, Then Verify
The Wright brothers' plane couldn't be verified as flight-capable until it flew. Verification had to wait for invention. This suggests a fundamental restructuring:
Phase 1: Exploration (High α)
- Let priors guide when uncertain
- Maintain multiple hypotheses
- Use weak filters (interesting? novel?)
- Delay commitment
Phase 2: Verification (Low α)
- Apply strict criteria
- Demand testable predictions
- Filter to survivors
- Consolidate learnings
But how to explore – controlled hallucinations.
NOTE: The methods below are inference-time techniques, not training-time. A recent training-time idea worth watching is FlowRL, which matches reward distributions rather than only maximizing expected reward. The methods here are also complementary to inference-level search strategies such as MCTS, Best-of-N (BoN), AggLM, and self-consistency (see Lilian Weng’s overview).
Approach 1: Temperature Scaling
The naive solution is temperature scaling—divide logits by a smaller number, get more "creativity":
# Temperature scaling: affects everything equally
logits = logits / temperature # Every token gets noisierBut this is like making someone creative by spinning them dizzy. Recent work like Polaris tries to adapt temperature based on entropy, but it still affects all tokens in a region equally.
Approach 2: Activation Steering
Instead of adding noise everywhere, activation steering identifies and explores specific semantic uncertainties:
def controlled_hallucination(prompt):
# Find uncertainty in activation space, not token space
# Where uncertainty can be measured as (a) hidden-dim deviations, (b) predictive entropy of logits
uncertain_dims = identify_high_entropy_dimensions(prompt)
# Create steering vectors toward unexplored regions
for dim in uncertain_dims:
steering = create_exploration_vector(dim)
# α adapts based on uncertainty magnitude
α = 0.2 + 0.6 * entropy(dim)
output = model.generate(
prompt,
steering_vector=α * steering,
layer=12 # Mid-network intervention
)Figure 6: uncertainty based activation steering
This is controlled hallucination—high α precisely where valuable, low α where we need grounding.
Approach 3: Bias as Semantic Navigation
However, we can steer activations beyond just uncertainty, and actually harness "bias". People often think bias is a bad thing, but bias is just activation steering with meaningful directions. Different "tastes" explore different regions:
# Extract bias from contrasting examples
scientific_vector = mean(scientific_examples) - mean(artistic_examples)
contrarian_vector = -expected_continuation # Explicitly seek opposite
# Apply bias via steering
def explore_with_bias(prompt, bias_type):
if bias_type == 'scientific':
return generate(prompt, steering=pattern_seeking_vector)
elif bias_type == 'contrarian':
expected = get_expected_direction(prompt)
return generate(prompt, steering=-expected)The failure isn't having bias—it's having frozen bias. We need portfolios of biases that rotate based on context.
The α Spectrum: A Visual Guide
α = 0.2 (Evidence Mode) α = 0.5 (Balanced) α = 0.8 (Exploration Mode)
"Verify this claim" "Complete this story" "What if these connected?"
├─ Fact-checking ├─ Standard generation ├─ Creative exploration
├─ Citation needed ├─ Context matters ├─ Priors lead
└─ Evidence dominates └─ Equal weighting └─ Hallucination usefulCurrent models are stuck at α ≈ 0.2 after RLHF—perpetual fact-checkers, never dreamers.
Approach 4: Gwern's Daydream Loop (System-Level Discovery)
Gwern's proposal is fundamentally different—it's not about making generation more creative, but about generation happening without prompting:
def daydream_loop():
"""Runs continuously in background, like default mode network"""
while True:
# Sample maximally distant concepts
concept_a = random_sample_embedding()
concept_b = sample_far_from(concept_a)
# Force connection without task pressure
connection = model.generate(
f"What connects {concept_a} to {concept_b}?"
)
# Weak filter - "interesting?" not "correct?"
if is_interesting(connection):
memory.add(connection)
# Most fail. A few survive. Patterns emerge.
sleep(1)This is the LLM equivalent of shower thoughts—undirected exploration when nobody's asking. Humans have ideas during downtime; LLMs only think on demand. Gwern suggests giving them idle cycles to explore:
- Cross-domain bridging: Connect unrelated fields
- Counterfactual generation: "What if history went differently?"
- Abstraction climbing: Find patterns across patterns
Closing thoughts
What we call “hallucination” is just unspent curiosity. Pretraining stocked the pantry; post-training locked the door. The fix isn’t more temperature—the trick her e is figuring out how to explore
Here’s the sharper lens:
- Exploration is policy, not noise. Treat creativity as where you aim the model, not how much you shake it. (Activation steering > global temperature.)
- Bias is a tool, not a sin. Curate portfolios of taste (scientific/artistic/engineering) and switch by uncertainty and task—like changing lenses, not beliefs.
- Verification lags invention. Put verification after exploration so the future can be true before it’s provable.
- Serendipity at system level. A daydream loop turns idle cycles into a compounding asset: a memory of bridges your prompts would never have asked for.