Anatomy of RL Frameworks
Part 1: A Deep Dive into OpenRLHF, VERL, Slime, Verifiers, and AReaL
Ever since DeepSeek-V3, the RLHF ecosystem has exploded with new frameworks for running RLVR training. Unlike conventional supervised learning, RL training poses unique MLsys challenges: we have to run inference and training in tandem. As the VERL paper points out, 80–90% of training time is spent just on sample generation—a bottleneck that drives most architectural choices.
In this part of series, I'll break down the five major frameworks shaping the space today—OpenRLHF, VERL, Slime, Verifiers, and AReaL (or Magistral or LlamaRL)—and the distinct trade-offs each makes. There are other notable projects like ROLL, RAGEN, and SkyRL that I didn't cover, since I haven't had the time to dig deep into their codebases or haven't had the opportunity to experiment with their frameworks.
In part 2 of the series, I aim to implement a minimal viable framework for a multi-turn tool use model that tries to incorporate the learnings from below: mostly for educational purposes, so don't go expecting a production-grade stuff there.
The Five Dimensions of Divergence
Before diving into code breakdown, here are the main point of divergence I see from the 5 frameworks. Let's compare the fundamental architectural choices that differentiate these frameworks:
1. Rollout Architecture: Engine vs Server
Engine Mode (co-located inference engine, same process/placement group as training):
- VERL (default), OpenRLHF: Rollout happens in-process or same Ray placement group; model weights are shared via memory or device communication (NCCL/CUDA IPC)
- Benefits: Minimal latency via direct memory access, no serialization overhead, enables weight sharing optimizations
- Trade-offs: Training and rollout must share resource allocation, harder to scale independently
Server Mode (disaggregated inference service):
- Slime (only mode), VERL agentic mode, Verifiers + PrimeRL: Rollout runs as separate HTTP/RPC service; training sends requests over network
- Slime and VERL use RPC; Verifiers uses HTTP to vLLM servers
- Benefits: Fault isolation (crash doesn't affect other components), independent scalability, heterogeneous hardware support
- Trade-offs: RPC/IO overhead, network bandwidth requirements, serialization costs
2. Weight Synchronization Strategy
Resharding (Device Mesh) – VERL Engine mode:
- Complex 3D tensor redistribution between training and generation phases using torch.distributed.redistribute.
- Implemented via sharding managers (e.g.,
FSDPVLLMShardingManager) to reshard actor model for generation - Achieves near-zero memory overhead by transforming single model in-place
- Only possible in engine mode with co-located processes
Direct Broadcast – OpenRLHF:
- Simple broadcast of new weights from trainer to inference workers via Ray or NCCL
- Leverages NVIDIA NCCL for multi-GPU collective communication or CUDA IPC for same-node memory transfer
- Less complex than resharding but requires full weight transfer
Versioned Updates – AReaL:
- Maintains asynchronous weight versions with staleness tracking
- Trainers push new weight versions to queue, rollout workers periodically load latest
- Old samples filtered or adjusted via staleness-aware PPO algorithm
- Reduces sync frequency by tolerating controlled staleness
Explicit Update APIs – Slime:
- Provides clear
update_weight()interfaces integrated with SGLang's server API - Converts Megatron-core checkpoints to huggingface format, using mbridge
- Due to SGLang optimizations — frequent weight updates, as we need, become very efficient as outlined in their blog
Standard vs Cross-Provider – Verifiers + PrimeRL:
- Verifiers alone: Just uses vLLM's standard weight updates (collective_rpc/NCCL)
- PrimeRL: Just uses vLLM's standard weight updates (collective_rpc/NCCL) with weight routed to vLLM via an orchestrator off a shared file system.
- Intellect-2 PrimeRL's different problem: Training across untrusted providers (vs datacenter training)
- SHARDCAST: CDN-style relays for cross-provider weight distribution
- TOPLOC: Verification for untrusted compute (detects tampering)
NOTE: Prime-rl aims to solve a different problem from the rest – training across clusters. Their main selling point is that they're a decentralized training framework.
External Middleware – Checkpoint-Engine:
- MoonshotAI's engine-agnostic weight sync middleware
- Updates 1-trillion-parameter models across thousands of GPUs in ~20 seconds
- It was used to train Kimi-k2 – my daily driver for open-source model due to its strong tool-call capabilities
- Powered by the fantastic mooncake-engine
[FUTURE?] Direct GPU <-> GPU Access (Only for the GPU-rich i.e IB-connected GPUs)
- Two-sided-connections (requires both sides to post ops: send/recv or read/write)
- GPUDirect-RDMA (UCX / ibverbs / NCCL): GPU↔GPU without going to the host's CPU
- e.g. LlamaRL's DDMA
- (Future?) One-sided connections (sender can push without peer posting receives)
- NVSHMEM – an entirely CUDA-level, one-sided comms that essentially makes all the GPU memory in the cluster globally addressable (see this cool blog implementing all-reduce on NVSHMEM)
- RDMA-based transfer (PoC built here)
3. Worker Organization
Monolithic Combined Worker – VERL:
- Single class (
ActorRolloutRefWorker) can host actor, rollout, and reference roles in one class—or any subset (actor+rollout, actor+rollout+ref)—or be split into separate workers. - It runs on the multi-controller (worker-group / intra-operator) side across GPUs, primarily to co-locate them in the same process group/node enables in-memory/NCCL weight transfer and SPMD rollout execution; the single controller only orchestrates the PPO loop and issues RPCs to these workers. (Will discuss more about verl's hybridengine later)
Role-Based Separate Workers – OpenRLHF:
- Distinct Ray actors for each role (Actor, Critic, Reward, Reference)
- Actor uses vLLM engine for generation, Critic/Reward use standard HF/DeepSpeed forward passes
- Recognizes asymmetry: generation needs specialized optimizations, scoring can use simpler models
Clean Three-Module Split – Slime:
- Strict separation: Trainer, Rollout, Data Buffer services
- Training (Megatron-LM) never directly calls inference engine (SGLang)
- Checkpoints weights and notifies rollout service to load them
- Data Buffer intermediates all data flow (prompts, rollouts, partial outputs)
Fully Asynchronous Pools – AReaL:
- Decouples into independent pools of rollout and training workers
- No fixed pairing between generation and training workers
- Rollout workers continuously generate on current policy
- Training workers continuously update on available data
- Relies on statistical smoothing and staleness control rather than strict sync
Separate Executables – Verifiers + PrimeRL:
- Verifiers standablone: TRL training + vLLM server separate executables
- With PrimeRL: FDSP2 Training + vLLM inference separate executables
4. Parallelism Model
Hybrid SPMD + RPC – VERL:
- Engine mode: Each GPU runs identical code (true SPMD) using NCCL for intra-node coordination (also using Ray's placement groups)
- Server mode: Training and inference run as separate processes over Ray RPC (via
actor_rollout_ref.rollout.mode=async)
Ray Placement Groups – OpenRLHF:
- Each component assigned to placement group for GPU control
- Can place actor and critic on same node or same GPU group for efficiency
- Supports colocated mode (all share GPUs in "hybrid engine" setup) or distributed across nodes
- Central Ray driver orchestrates workflow
Native Distributed Actors – Slime:
- Uses Ray actors with simpler configuration than OpenRLHF
- Single flag
--colocatetoggles between colocated and decoupled modes - Designed primarily for decoupled case to maximize throughput
- Leverages Ray's async execution (
.remote()futures) naturally
Decoupled Async Pools – AReaL:
- All generation workers run independently of training workers
- Producer-consumer model: rollout pushes to queue, trainers pull batches
- Dynamically balances rollouts vs training to keep staleness bounded
- Achieves up to ~2.77× speedup over sync baselines
Async FSDP Without Ray – Verifiers + PrimeRL:
- FSDP2 training
- vLLM inference
- Training and inference are separate executables – training and inference runs on separate pools.
5. Data Flow Pattern
Tensor-Centric "DataProto" – VERL:
- Unified protocol object encapsulates batches and metadata
- Uses decorator to fan-out the
DataProtoacross DP ranks (@dispatch) and fan-in the results back into a singleDataProto - Enforces strict schema (nested TensorMap) at cost of rigidity
Ray Object Store – OpenRLHF:
- Shared memory object store for zero-copy data passing
- Batches put into store, references (object IDs) passed to workers
- Avoids repeated serialization of large tensors
- Weight updates broadcast via object references or Ray's NCCL APIs
File-backed Buffer – Slime:
- Data Buffer backed by disk (Parquet or JSONL) for large-scale runs
- Trainer reads batches from buffer, rollout workers append samples
- Training loop unaware of generation mechanism details
- Supports partial rollouts crucial for long outputs or tool interactions
Streaming Queue – AReaL:
- Endless stream of experiences rather than epoch-based dataset
- Staleness timestamp with each sample for filtering/down-weighting
- Dynamic micro-batches keep all GPUs busy with minimal waiting
- Completed rollouts immediately placed in async queue
File Exchange Between Executables – Verifiers + PrimeRL:
- Training and inference are separate programs exchanging files
- Prime-RL:
- Rollout directed by an orchestrator.
- Weights are passed via a shared file system.
- Intellect-2 style
- Rollout data via Parquet files between executables
- Weights distributed via SHARDCAST relay servers
- Handles 2+ step staleness from cross-provider delays (not sure how they handle staleness though)
Part 1: VERL - The Hybrid-Controller Architecture
Design Philosophy
VERL is the open-source implementation of HybridFlow. It decouples control flow from computation flow: a single controller (driver) runs the RL loop, while multi-process worker groups (actor/rollout/ref/critic) execute heavy compute. The docs state: "verl is designed to decouple the control flow of RL algorithms and the implementation of computation engines" [HybridFlow guide].
Dual Rollout Modes
VERL supports two distinct rollout modes via configuration (e.g., actor_rollout_ref.rollout.mode=async):
HybridEngine Mode (Co-located/SPMD):
- Actor and rollout are co-located in the same worker process group to enable in-memory/NCCL weight transfer and SPMD-style inference [FSDP workers]
- VERL adapts vLLM to run in SPMD within workers; SGLang is also supported with placement constraints [SGLang worker]
- Generation steps are synchronized across the DP group (vectorized split→compute→gather) - high throughput on uniform workloads but creates head-of-line blocking if any request lags (e.g., tool latency), which motivates the async path for agentic RL. [single_controller design]
⚠️ CRITICAL LIMITATION: Engine mode requires synchronous batch processing - all requests must complete before any can proceed. This makes multi-turn RL with tools practically infeasible. Example: If one conversation in a batch of 100 needs a 5-minute tool call, all 100 conversations (and GPUs) sit idle waiting, potentially wasting 90%+ of compute cycles.
AsyncServer Mode (Server-based async rollout):
- Rollout runs as an async server (Ray Serve/FastAPI), decoupled from training [Agentic RL]
- Each conversation progresses independently and returns results out of order - required for multi-turn agent loops and tools
- Avoids GPU idling during slow tool calls (HTTP APIs, code exec) [Agentic RL]
- Supports request-level load balancing across inference servers
- NOTE: read more about [Agent Loop], which was used to reproduce Retool training recipe.
{kind=link}
✅ WHY ESSENTIAL FOR TOOLS: Async rollout prevents GPU starvation during tool calls:Tool latencies vary wildly (API calls: 100ms-10s, code execution: 1ms-60s)GPUs continue processing other conversations while waiting for tool responsesEach conversation flows naturally without blocking othersMaintains high utilization even with heterogeneous workloads
Weight Synchronization in the two modes:
- HybridEngine: Can reshard in-place between training layout (e.g., FSDP/DP×TP) and rollout layout (vLLM TP/replicas) via sharding managers (e.g
FSDPVLLMShardingManager) without duplicating weights and uses NCCL verbs [FSDP workers].
NOTE: Actor and rollout are co-located (same worker group)
# Illustrative example: Training vs Generation configurations
# Training: DP=2, TP=8 (16 GPUs total for 70B model)
# Generation: DP=16, TP=4 (same 16 GPUs, more parallel samples)
# Controller calls generate_sequences on ActorRolloutRef worker group
# 1. Sharding manager reshards from training layout to vLLM layout
# 2. vLLM runs SPMD generation across the group (or mock SPMD for SGlang i.e only rank 0 runs and everything else is None)
# 3. On exit, reshards back to training layout for PPO updatesWeight resharding at the very core of 3D-HybridEngine (see the code her e
- AsyncServer: TP configured per inference server (vLLM/SGLang)
- vLLM: Set
tensor_parallel_sizeon servers; smaller TP + more DP replicas often better for throughput - SGLang: Async entrypoint lives on first GPU of each TP group, AsyncServer calls that rank remotely
- Weight sync requires explicit server weight-update path (e.g.,
load_weights) unlike HybridEngine's in-place reshard
- vLLM: Set
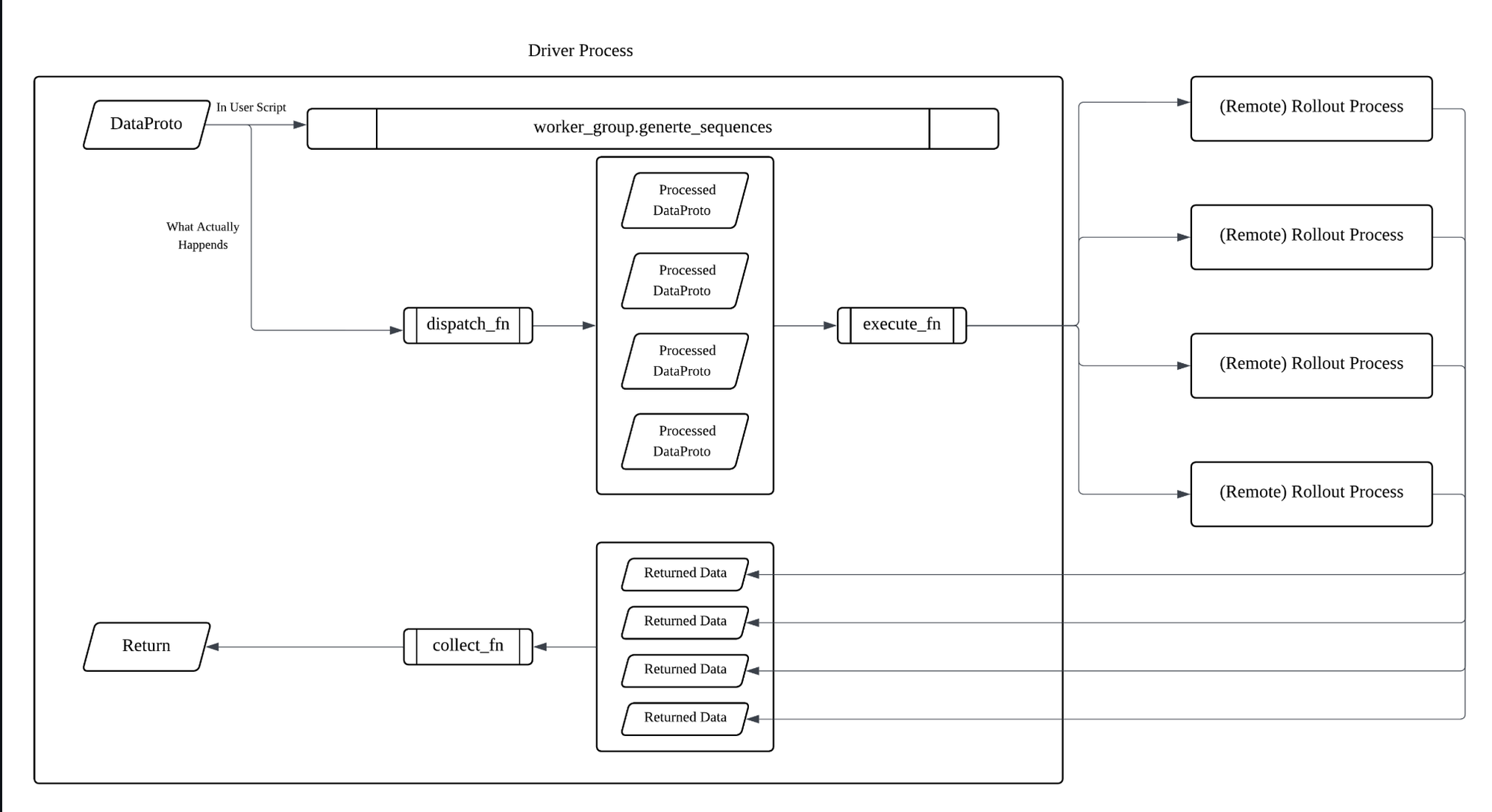
Four-Phase PPO Training Loop
VERL implements the standard PPO loop in a distributed fashion:
- Load Data: Fetch prompts (controller process)
- Rollout/Generate: Worker group via
actor_rollout_ref_wg.generate_sequences(DataProto)- VERL automatically splits → runs → gathers across DP ranks (using @dispatch) [HybridFlow guide] - Update Models: Actor/critic updates on worker groups
- Make Experience: Controller assembles rewards/advantages using actor/ref log-probs and critic values from workers (via @collect)
All controller↔worker calls pass a DataProto (tensor batch + metadata), with decorated worker methods declaring their dispatch/collect behavior. This enables both batched lockstep (HybridEngine) and out-of-order streaming (AsyncServer) [single_controller design]
Beyond Single-controller
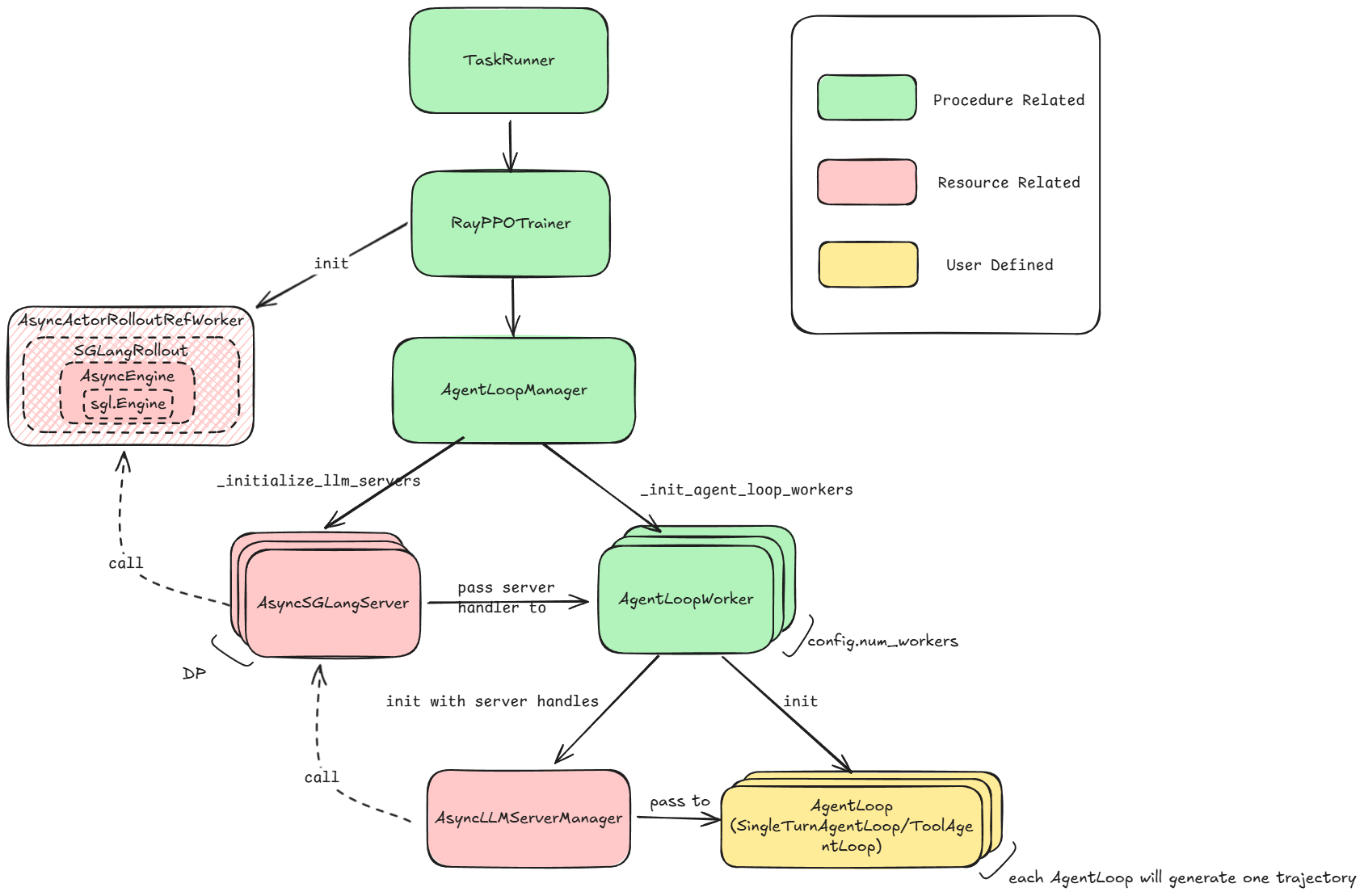
Why the “do-it-all” worker existed. Early VERL centered on 3D-HybridEngine: a single controller orchestrates inter-node, while multi-controller worker groups run compute intra-node. Because HybridEngine assumes co-location for in-memory/NCCL resharding, it was performance-optimal to fuse roles into one surface. Thus ActorRolloutRefWorker owned generation backends, PPO updates, reference-policy log-probs, and resharding/dispatch glue—great throughput, but brittle for tool-use training (fsdp_workers.py L136) [Figure 1].
What changed with AgentLoop. To handle multi-turn/tooling (long-tail latencies from tool calling), VERL pulled generation out into asynchronous, per-conversation servers (vLLM/SGLang). AgentLoop runs the conversation state machine so each dialogue advances at its own pace, returns out of order, and is re-assembled for training (docs, agent_loop.py L719)—avoiding lockstep batching, keeping GPUs busy during tool calls, and aligning with ReTool-style multi-round workflows [Figure 2].
Where it lands today. VERL exposes two rollout modes:
- Engine (co-located/SPMD): maximal in-memory weight sharing via HybridEngine reshard; best for synchronized, tool-free decoding.
- Async (server-based): AgentLoop + inference servers for tool-use training and multi-turn rollouts without head-of-line blocking.
Part 2: Slime — the elegance of separation
Design philosophy
Slime (Tsinghua & Zhipu AI) leans hard into modularity and SGLang-native serving. It separates training and inference concerns and lets you compose your own rollout pipeline around an HTTP router instead of a monolithic worker. See the official docs home and usage guide: slime docs, usage guide.
Unlike Verl, Slime has no single controller; training (Megatron) and rollout (SGLang) are decoupled services joined by the DataBuffer and the router.
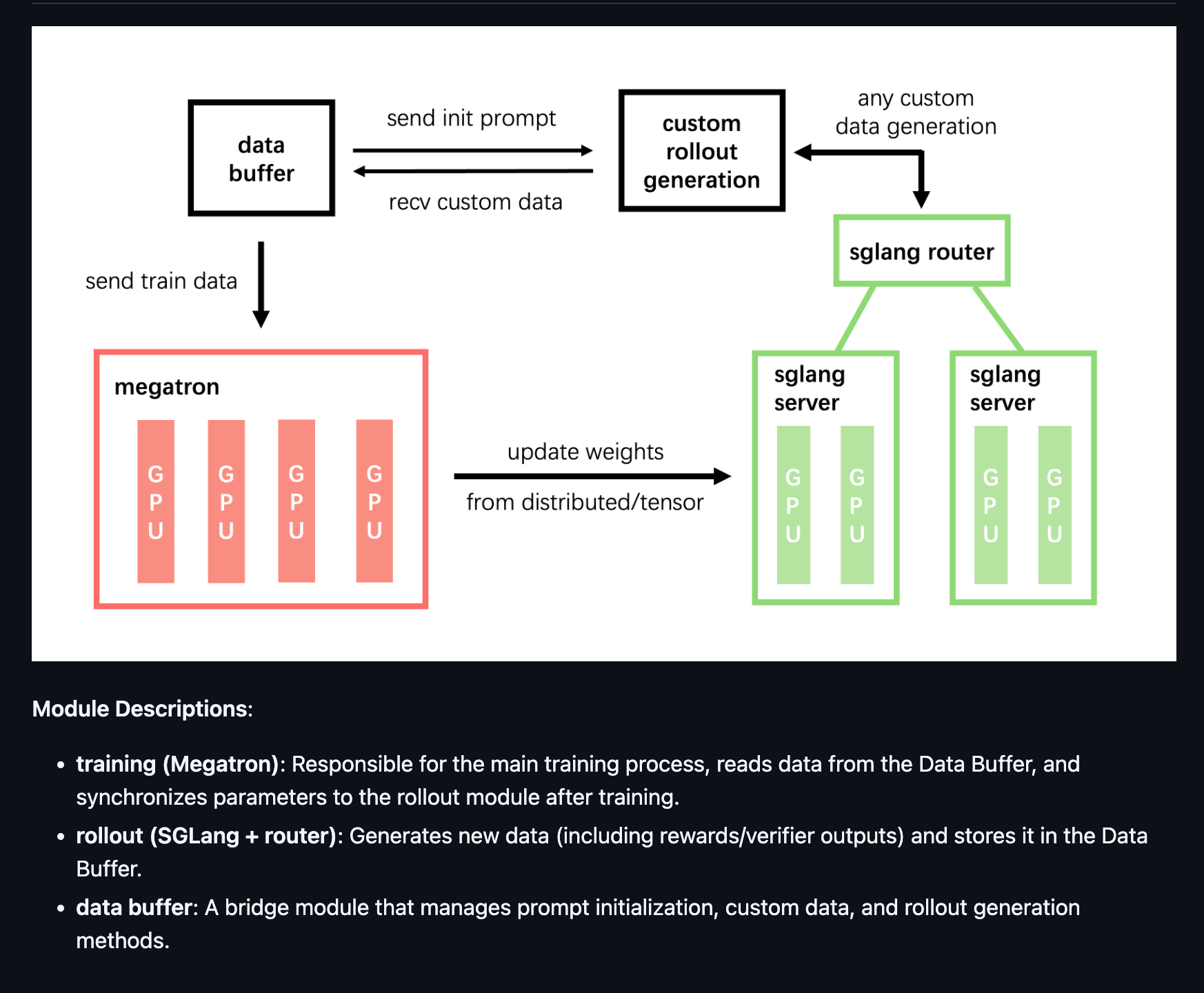
Three-service architecture (+ router)
- Training service (Megatron-LM). You launch Megatron via
train.py/train_async.py, set TP/PP/EP, and read/writetorch_distcheckpoints.
– Entry points:train.py,train_async.py - Rollout service (SGLang servers + router). Slime treats inference as its own service layer. A RolloutManager targets/route to SGLang servers via the router, handling request scheduling, backpressure, and streaming results; your rollout function just hits the router HTTP API (e.g.
/generate) - A global Data buffer (bridge). Rollout writes samples (including partials when you interrupt for tools); training reads batches from the buffer. This lets both sides run at different speeds without blocking.
Key distinction: Even with--colocate, Slime still loads Megatron and SGLang as separate processes and communicates over HTTP; you just share nodes/GPUs under Ray resource allocation.--colocateflag notes
Checkpoints conversion between frameworks
Slime’s boundary is Megatron ↔ SGLang(HF). You train/load Megatron checkpoints and serve HF weights on SGLang; Slime supports conversion between HF and Megatron’s torch_dist so training and serving can use different formats, and uses mbridge to bridge the two.
Weight update flow:
- Megatron trains & saves step checkpoints (
torch_dist). - Convert/sync to the HF checkpoint that SGLang expects using mbridge.
- Rollout servers receive a weight update (reload).
Docs call out that SGLang is initialized from HF and params are synced from Megatron before step-0 (and on resume), i.e., serving doesn’t need the freshest HF folder if you rely on Slime’s sync.
Partial rollout & aborts (crucial for tools / multi-turn)
Slime’s default rollout is asynchronous and supports partial rollouts:
- The provided
generate_rolloutis asyncio-based, supports dynamic sampling and mid-turn interruption. [see more: “Custom Rollout Function”] - It uses SGLang’s HTTP API (router) and can call
/abort_requestto interrupt generation mid-way, capture partial text, run a tool, then resume. (SGLang has a first-party/abort_requestendpoint; there’s active work to propagate it via the router.)
This is why Slime is “server-native”: no lockstep batch; each request is a separate HTTP flow that can be aborted/resumed. For multi-turn recipes see [Fully Asynchronous example] [Retool example]
Fast Weight Syncing
In recent months, the Slime team has made co-located mode extremely fast. In this mode, Megatron and SGLang share GPUs but run as separate processes. Because training and inference often use different parallelism layouts (e.g., Megatron TP/PP/EP vs. SGLang DP/EP), Megatron must first gather distributed tensors before exporting them via CUDA IPC handles. SGLang then maps these handles and reloads weights through the/update_weights_from_tensor API — avoiding CPU↔GPU copies and reusing the same serverized stack as production inference. With optimizations like Tensor Flattening, Bucketing, and faster load paths for MoE models, Slime reduced weight transfer to just 7 s for Qwen3-30B-A3B (8×H100). (Read Biao’s blog for more info).
Why this design feels different from VERL
- VERL’s HybridEngine favored a co-located monolith for in-memory NCCL weight movement and SPMD rollout; Slime always runs a server boundary and treats rollout as HTTP-driven IO (with router LB and per-request control).
Part 3: OpenRLHF - The Ray-Powered Workhorse
Design Philosophy
OpenRLHF gained popularity for being both easy-to-use and high-performance. It pragmatically combines existing tools (Ray, vLLM, DeepSpeed) rather than building from scratch. They treat training and serving as two separate resource pools.
Hybrid Engine Configuration
OpenRLHF's "hybrid engine" refers to colocating multiple components in the same Ray placement group, so they operate components like Actor and Critic in the same GPU group.
Weight synchronization in hybrid mode uses:
- NCCL or CUDA IPC: "Weight synchronization between the Actor and the vLLM engine is handled via high-performance communication methods, such as NVIDIA Collective Communications Library (NCCL) or CUDA Inter-Process Communication (IPC) memory transfers in hybrid engine settings"
- Custom WorkerExtension: Handles weight updates via IPC handles for zero-copy transfers
Actor-Critic Asymmetry
OpenRLHF recognizes different computational needs:
- Actor: Uses vLLM with Ray executor backend for generation
- AutoTP: Automatically partitions models across GPUs without manual configuration
- Custom WorkerExtension for efficient weight updates via IPC
- Critic/Reward: Use standard HF/DeepSpeed for simple forward passes
- DeepSpeed/ZeRO-3: Memory optimization approach for training
- Reference: Often frozen, can be colocated with Actor for efficiency
Part 4: AReaL/Magistral – Async RL
Design philosophy
AReaL (Ant Research) maximizes hardware utilization by fully decoupling generation from training: rollout workers stream tokens continuously while trainers update whenever batches are ready.
By contrast, a sequential pipeline launches a batch of prompts, waits for every sequence to finish, then updates weights for both trainers and generators before starting the next round—leaving GPUs idle on the long-tail of slow, verbose trajectories (see Figure 4).
To keep this asynchrony stable, AReaL adds algorithmic guardrails for staleness: it filters overly stale samples, adapts PPO clipping to version drift, and regularizes toward the current policy. Net effect: you break the strict 1:1 coupling between experience collection and updates without blowing up KL or variance.
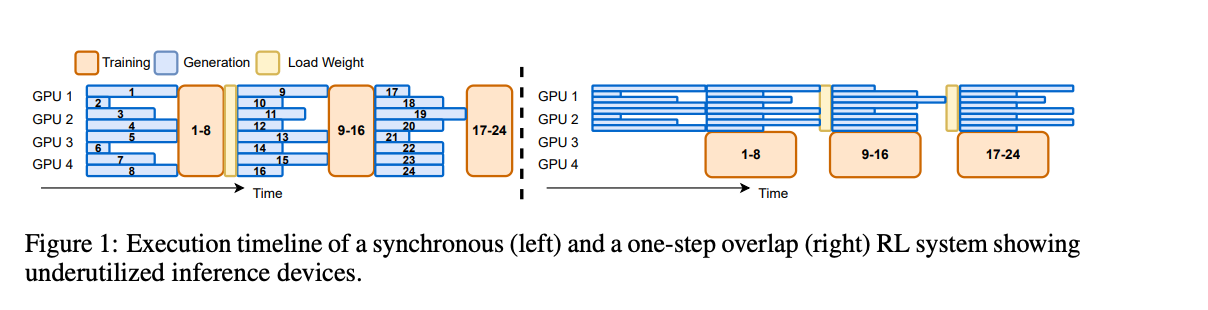
Read the paper for more info!
Four-component architecture
- Rollout workers. Stream trajectories using the latest available weights; can be interrupted mid-decode when fresher weights land, where we'll discard old KV cache and recompute with the latest weight.
- Trainer workers. Consume whatever’s in the buffer and step the policy; no global barrier with generators.
- Reward service. Async, parallelizable (expensive verifiers OK).
- Staleness controller. Feedback loop to balance rollout/training throughput and keep average staleness bounded (not zero).
Staleness-aware PPO (decoupled objective)
Because batches may mix multiple policy versions, AReaL modifies PPO to remain stable off-policy:
- Filter samples beyond a staleness threshold η\etaη.
- Adjust clipping around a decoupled objective tailored to stale data.
- Add KL/staleness regularization proportional to version difference.
Net effect: controlled off-policy learning with bounded divergence while preserving async throughput.
Interruptible rollouts (don’t waste compute)
Rollout workers periodically check for better weights and can abort long decodes when staleness crosses a threshold; old KV is dropped and recomputed under fresh weights before continuing. This turns wall-clock “laggards” into future-proofed samples and empirically boosts end-to-end throughput. (Related ecosystem work has added “interrupt/abort on weight update” primitives to serving stacks.)
Dynamic throughput control
If trainers starve, allocate more GPUs to generation or ramp request rate; if the buffer floods, pause rollouts or scale trainers. The controller aims for a bounded average staleness while optimizing steps/sec—effectively a feedback control loop over the pipeline.
An aside: Magistral
Interestingly, Magistral also adopts a similar asynchronous RL pipeline—decoupling generation and training—but differs in three key ways (see Figure 5 too):
- How it does async
- AReaL: Interrupt long generations → drop old KV → re-prefill with fresh weights → continue.
- Magistral: Do not interrupt → hot-swap weights mid-gen → keep decoding with a slightly stale KV (no refresh).
- Data implications
- AReaL: Produces off-policy fragments; stabilized with staleness-aware PPO/decoupled objective + staleness filter ηηη.
- Magistral: Stays closer to on-policy; accepts brief KV/weight mismatch windows.
- Algorithmic tweaks
- AReaL: Staleness filtering, adjusted PPO clipping around a decoupled objective, KL/staleness regularization.
- Magistral: GRPO with Clip-Higher, group/length normalization; no KV refresh, no explicit KL term.
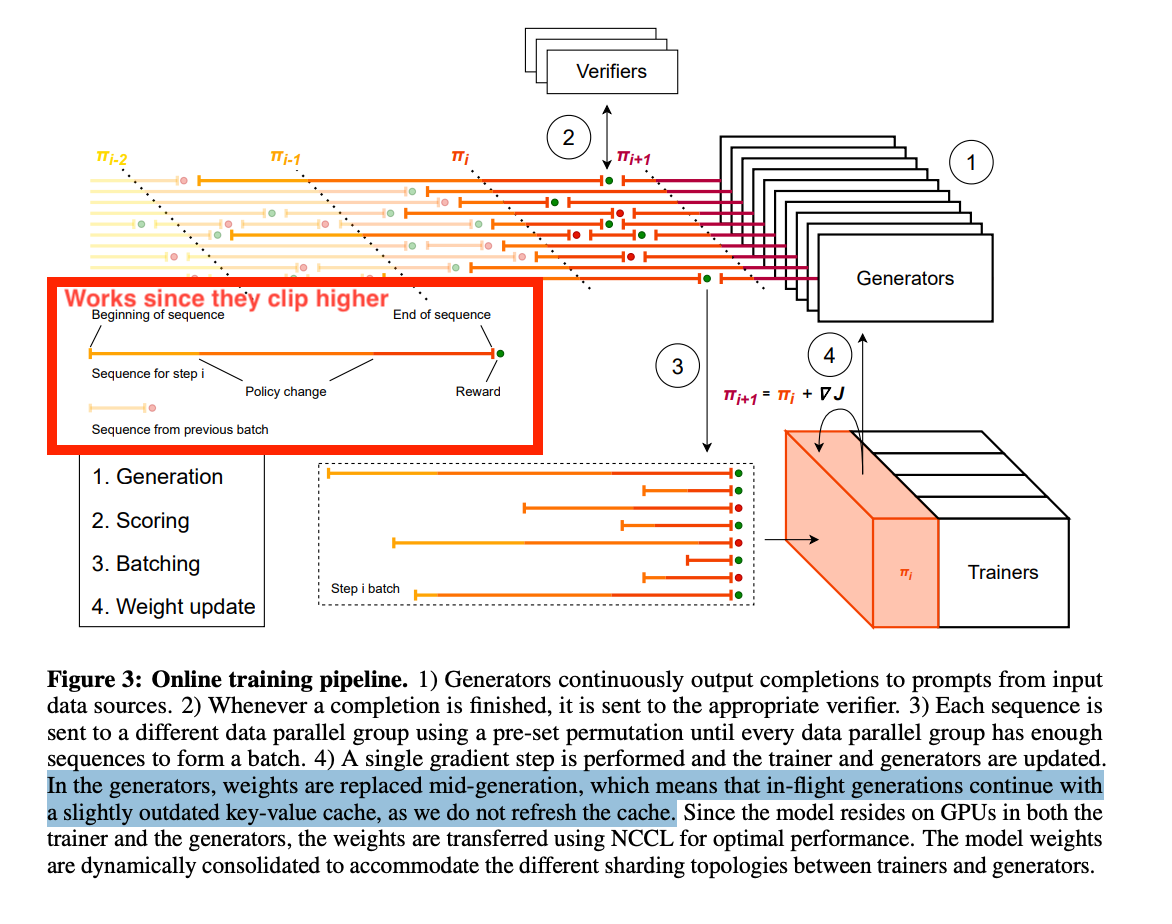
In essence: AReaL trades interruptions + math guardrails for fresher policy data; Magistral trades mild KV staleness for uninterrupted throughput and simpler training.
For technical details on async RL vs request-level async, see Appendix B.
Part 4.5: LlamaRL — Async RL with GPU Direct Memory Access
Design Philosophy
- Controller-first design. One lightweight PyTorch controller initializes ranks/channels, orders weight+data ops (broadcast/scatter/gather), ticks actor/generator, trainer, reward, ref independently, and handles minimal checkpoint/retry—no global barriers.
- Fully async & off-policy. Generation and training proceed independently; the trainer consumes stale rollouts with off-policy corrections (inspired by Impala, see Figure 6).
- Scales wide. Built to span dozens → thousands of GPUs.

Colocation & placement
- Flexible placement. Executors can be co-located with training (low-latency) or remote (elastic/heterogeneous). The controller schedules over channels regardless of where they live.
DDMA (“zero-copy”) weight sync — the gist
- Classic path (slow):
trainer → CPU → network → CPU → GPU - LlamaRL path (fast):
device → fabric → device- Push sharded parameters GPU↔GPU over NVLink (intra-node) / InfiniBand (inter-node), no host staging, end-to-end device-memory collective.
- NOTE: it's important that training and generation share a compatible shard layout, so weights move slice-to-slice (GPU→GPU) with no reshaping/host copies (i.e going to the CPU); mismatches force resharding (extra all-to-alls/transposes), adding latency.
The paper unfortunately didn't mention how they perform the gpu <->gpu connections. Fundamental RDMA ibverbs? NVSHMEM?
Results (summary)
- Up to 10.7× speedups vs DeepSpeed-Chat-like baselines at 405B, plus a theoretical proof that async design yields strict RL step-time speedup.
Positioning vs AReaL/Magistral
- Similar: fully async, decoupled pools, continuous streaming.
- Different: a single PyTorch controller + GPU-native, shard-aligned DDMA for fast, CPU-free weight sync (device→fabric→device).
Part 5: Verifiers + PrimeRL - Orchestrated Server-Mode RL
Design Philosophy
Verifiers provides OpenAI Gym-like environments for LLM tasks with vLLM server-based rollout. PrimeRL adds an orchestrator that coordinates distributed learners and rollout executors with efficient parameter distribution and deterministic inference placement.
Architecture Components
- Environment abstractions: OpenAI Gym-like API for LLM tasks
- vLLM server wrapper: Rollout via HTTP to vLLM servers
- MultiTurnEnv: Handles dialogues and tool use
- Parsers & Rubrics: Extract structured data and compose reward functions
Prime-RL splits reinforcement learning into three simple pieces, tied together by a shared filesystem and HTTP APIs:
- Orchestrator (orchestrator.py): Acts as the controller – routes rollout requests to the inference server, buffers results (buffer.py), and watches for new checkpoints. It also checkpoints its own state (rollout step, buffer, last ckpt) so it can recover cleanly.
- Inference via vLLM (server.py): Runs as a persistent HTTP service. The orchestrator tells it when a new checkpoint appears, and vLLM simply reloads weights from the shared output directory. Scaling is handled by vLLM’s built-in data-parallel load balancing.
- Training with FSDP2 (train.py): Launched with
torchrun(one process per GPU). FSDP2 shards model state, runs the RL update, and periodically saves checkpoints into the shared directory.
Trainer and Orchestrator are co-located on the same node, and both are checkpoint-ed – trainer (model weights and optimizer states) and orchestrator (rollout/control state). This way, if one process dies, it can restart and stay consistent with the other.
Weights reach inference via a very simple contract: trainer saves → orchestrator detects → inference server reloads. The filesystem is the handshake.
From the Intellect-2 paper, there might be an additional infra layer (behind the scenes) to make the prime-rl scalable to heterogeneous gpus, across different data centers, with the following addition:
- SHARDCAST: Efficiently distributes sharded model parameters (similar to standard data chunking/reassembly)
- TOPLOC: Ensures inference determinism across heterogeneous hardware (critical since quantization operations are non-associative)
- Rollout data passed along with a parquet
NOTE: Interestingly, the paper acknowledges that inference workers are often two steps behind the latest policy due to the cost of broadcasting large weight updates (Fig. 6). As it stands, they highlighted the broadcast bottleneck but doesn’t spell out a mitigation strategy on how to correct for this off-policiness – however this seems to be configurable in their codebase with the (--async_level) i.e 0 == fully in-sync at the cost of latency.
System-Level Insights
The Trade-off Matrix
When choosing between frameworks, consider these detailed trade-offs:
Memory Efficiency vs Latency:
- VERL's resharding: Highest memory efficiency through in-place transformation, but adds resharding latency
- OpenRLHF: Moderate memory use with full model copies, moderate latency via NCCL/IPC
- AReaL: Higher memory use (multiple versions), but zero synchronization latency
- Checkpoint-Engine: Enables all approaches with 20-second updates
Flexibility vs Performance:
- Slime: Maximum flexibility with clean interfaces, accepts RPC overhead for modularity
- VERL: Less flexible due to monolithic design, but optimized for peak performance
- Verifiers + PrimeRL: Built for decentralized providers, async-first design trades some control for scale
Complexity vs Robustness:
- AReaL: Most complex system (staleness control, async scheduling), highest throughput
- OpenRLHF: Moderate complexity using existing tools, production-proven reliability
- Verifiers + PrimeRL: Added complexity from verification (TOPLOC) and relay distribution (SHARDCAST)
Synchronous vs Asynchronous Trade-offs:
- Sync (traditional PPO): Deterministic, easier debugging, wastes GPU cycles on stragglers
- Async RL (AReaL): 2-3× throughput improvement, requires staleness handling (see Appendix C)
- Async Rollout (VERL server mode, Slime): Essential for multi-turn, adds state management complexity
Looking Ahead: The Convergence
These five frameworks demonstrate there's no universal solution for RLHF. Each makes different trade-offs suited to specific needs. The rapid open-source evolution benefits everyone - what took months to implement last year is now a configuration flag.
The collective lessons:
- Weight sync is THE bottleneck. Every win attacks parameter movement.
- Async is the future. For both RL (training⇄rollout decoupled) and request-level rollout (multi-turn/tools).
- Middleware is rising. Engine-agnostic sync layers (e.g., Checkpoint-Engine) are becoming standard.
- Separation scales. Disaggregate training, serving, and orchestration.
Emerging Patterns
Looking at recent developments:
- Frameworks converging on async rollout for multi-turn
- Weight update middleware becoming standalone services
- Environment abstractions standardizing across frameworks
- Trace-based debugging becoming essential
The Next Generation
1) Pipeline weight loading (hide latency — like Kimi-K2)
- Dual-bucket pipeline: H2D ↔ broadcast ↔ reload so Bucket A reloads while Bucket B transfers.
2) GPU-direct weight transfer
- NCCL over UCX/InfiniBand first (easy, stable) with bucketed broadcast/all-gather on device pointers.
- Possibly, NVSHMEM (one-sided, GPU-initiated) or raw RDMA.
Both are harder to debug, but gives more control.
However, for GPU-direct weight transfer, shard-layout between training and generation needs to be at parity
Align training & generation TP/PP/FSDP layouts so updates are slice-to-slice (no reshapes, no extra all-to-alls).
3) Continuous experience collection
- Use streaming queues instead of epochs (AReaL/Magistral style) so train and generate never block each other.
4) Async implies off-policy— to fix it we need to answer:
- When to apply new weights:
- Refill (AReaL): interrupt & re-prefill long tails.
- Hot-swap (Magistral): keep decoding, accept brief KV/weight mismatch.
- Push cadence: drift-triggered (held-out KL threshold) or every K steps, whichever comes first.
- Corrections: IMPALA-style (clipped importance weights, V-trace-like tempered targets), optional KL and staleness filters.
6) Heterogeneous fleets by default
- A100s train, H100s serve; the middleware/transport abstracts the fabric so the loop stays device→fabric→device.
Appendix A: Checkpoint-Engine Deep Dive
MoonshotAI's Checkpoint-Engine (docs) solves the critical bottleneck in RLHF: weight synchronization. They report updating Kimi-K2 (1T params) across hundreds–thousands of GPUs in ~21–22 s with vLLM via a pipelined H2D → Broadcast → Reload design; it falls back to serial when memory is tight.
Core Architecture
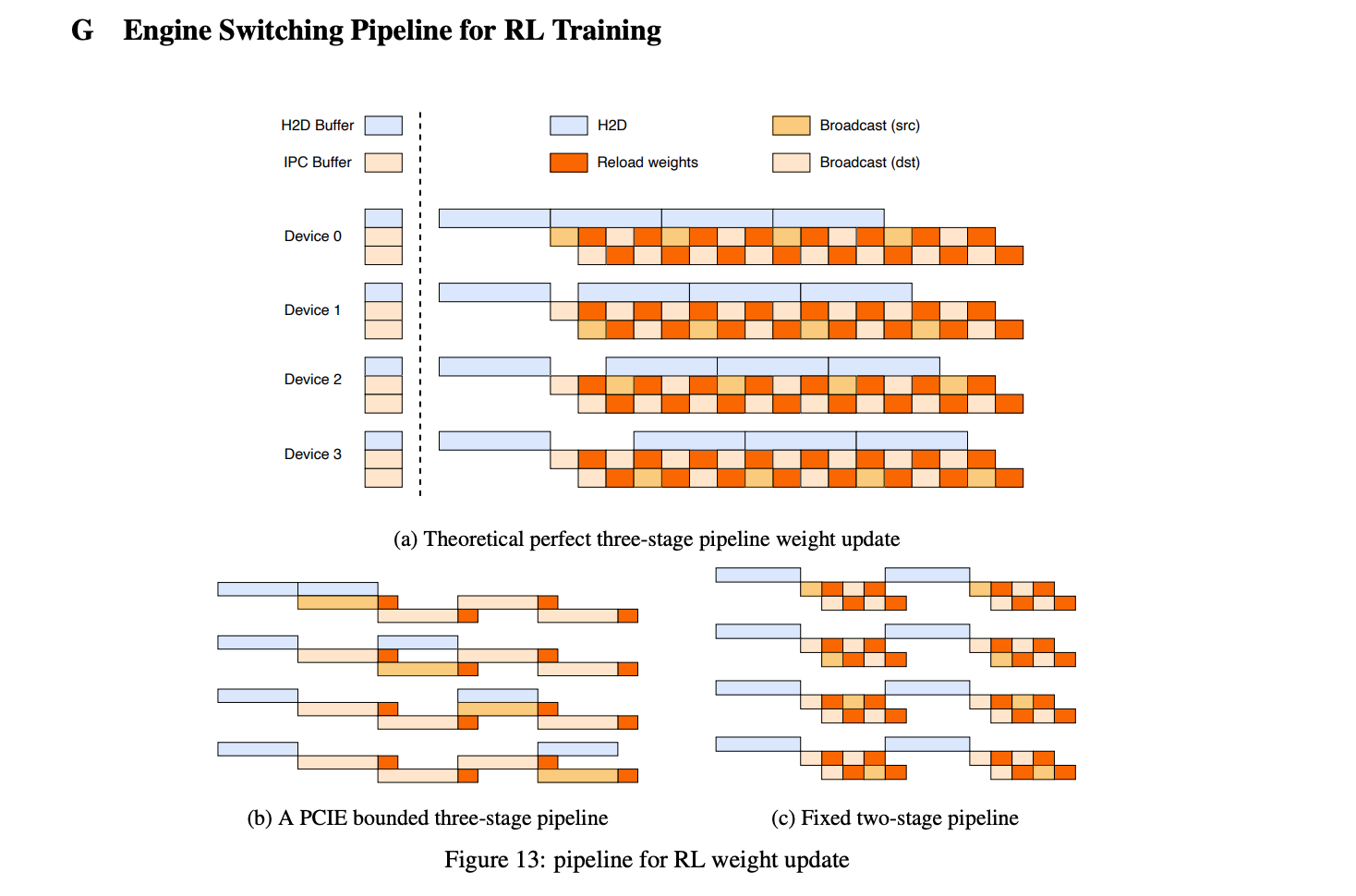
Three-Stage Pipeline:
- H2D: Move sharded weights from CPU/DISK → GPU staging.
- Broadcast: NCCL (or equivalent) blast to all nodes (CUDA IPC buffer exposed to engines).
- Reload: Each engine copies the shards it needs from the broadcast buffer into its live params, using vLLM integration through
/collective_rpc(e.g.,reload_weights)
These stages execute in a pipeline: While one batch is broadcasting, the next is loading from host memory, and the previous is being copied by the inference engine. This overlapping keeps all hardware utilized. Falls back to serial execution when GPU memory is constrained.
Two Update Modes (Solving Different Problems)
Broadcast Mode (for synchronized training):
- All inference instances receive weight updates simultaneously
- Optimized for standard RLHF iterations where all workers need the same model version
- Achieves ~20s updates for 1T parameter Kimi-K2
P2P Mode (for fault tolerance and elastic scaling):
- New instances can join mid-training and receive weights from existing instances
- Handles GPU failures gracefully - replacements can sync without restarting
- Enables dynamic scaling without stopping training
- Uses peer-to-peer transfer to avoid bottlenecking the trainer
Key Performance Metrics
| Model | Scale | Broadcast Time |
|---|---|---|
| Qwen3-235B | 8xH800 | 6.75s |
| Kimi-K2 | 256xH20 | 21.50s |
Works with vLLM (/collective_rpc endpoint) and SGLang (/update_weights endpoint). Part of the broader Mooncake platform including Transfer Engine (TCP/RDMA/NVMe-oF support) and P2P Store (decentralized with etcd metadata).
Appendix B: The Async Spectrum
Two Types of "Async" in RLHF
The term "async" in RLHF contexts refers to two distinct concepts that often confuse newcomers:
1. Async RL (Training-Rollout Decoupling)
What it means: Training and rollout (generation) happen independently without strict synchronization.
Implementations:
- AReaL: Fully decoupled pools with staleness tracking
- Slime: Training continues while new rollouts generate
- VERL: Currently synchronous, async RL planned for future versions
Benefits:
- Training never waits for rollout completion
- Rollout never waits for weight updates
- 2-3× throughput improvement typical
Challenges:
- Staleness management required
- Off-policy corrections needed
- More complex debugging
2. Request-Level Async (Async Rollout)
What it means: Individual requests/conversations progress independently during generation, not synchronized in batches
Implementations:
- Slime: Native support via SGLang's async serving
- VERL Server Mode: Each conversation progresses independently
- VERL Engine Mode: Currently synchronous batch processing only
Benefits:
- Essential for multi-turn dialogues with tools
- No GPU idle time waiting for slowest request
- Natural conversation flow
Challenges:
- Complex state management
- Dynamic batching overhead
- Memory allocation complexity
Why Both Matter
For Multi-Turn RL with Tools:
- Request-level async prevents GPU starvation during tool calls
- Async RL prevents training stalls during long rollouts
- Combined, they enable continuous learning on heterogeneous workloads
Example Scenario:
Without async rollout: 100 conversations, 1 makes API call → 99 GPUs idle for 5 seconds
With async rollout: 100 conversations progress independently → Full GPU utilization
Without async RL: Training waits for all 100 conversations to complete → Wasted compute
With async RL: Training processes available data immediately → Continuous learning
Implementation Status
| Framework | Async RL | Request-Level Async | Off-Policy Support |
|---|---|---|---|
| VERL | ❌ | ✅ (server mode only) | One-step off-policy |
| Slime | ✅ | ✅ (native) | One-step off-policy |
| OpenRLHF | ❌ | ❌ | ❌ |
| AReaL | ✅ (core design) | ✅ (via SGLang) | Full staleness-aware PPO |
| LlamaRL | ✅ | ✅framework-level (executors run asynchronously) | AIPO (Impala-style corrections) |
| Verifiers | ❓ | ✅ (via asyncio) | One-step off-policy |
| PrimeRL | ✅ (2-step async) | (separate executables) | One or Two-step off-policy |
The Future is Async
Both types of async are converging as standard requirements:
- Tool use demands request-level async
- Scale demands async RL
- Modern frameworks must support both
The combination of async RL and request-level async, enabled by fast weight sync (Checkpoint-Engine), represents the future of RLHF infrastructure.
Appendix C: Off-Policy Data Handling
A critical challenge in async RL is handling off-policy data - samples generated from older policy versions. How frameworks handle this determines whether they can leverage async architectures effectively.
Framework Approaches
AReaL - Full Staleness-Aware PPO:
- Tracks exact version difference for every sample
- Adjusts PPO clipping range based on staleness level
- Adds KL regularization proportional to version difference
- Interruptible generation explicitly creates off-policy data, which is handled gracefully
- Can leverage data from multiple policy versions ago
PrimeRL - Two-Step Async Without Tracking:
- Rollouts typically 2+ steps behind due to cross-provider broadcast delays
- "Rollouts are collected from policy weights from two or more RL steps prior"
- How they handle staleness isn't detailed in the paper
- Designed for cross-provider scale where staleness is unavoidable
Verifiers - One-Step Off-Policy:
- Supports training on data from the immediately previous policy
- Simpler than full staleness tracking but still enables some async benefits
- Sufficient for moderate async deployments
VERL - Limited Off-Policy Support:
- AgentLoop enables async rollout (server mode) but not async RL
- Has one-step off-policy recipe similar to Verifiers
- Primarily designed for on-policy training
Slime & OpenRLHF - On-Policy Only:
- Require strict synchronization between training and generation
- Cannot effectively use stale data
- Async rollout in Slime doesn't translate to async RL benefits
Why This Matters
The ability to handle off-policy data directly determines:
- GPU Utilization: On-policy frameworks waste cycles waiting for fresh data
- Throughput: AReaL's 2.77× speedup comes from never waiting
- Scale Efficiency: Off-policy support enables true decoupling of training and generation
Without proper off-policy handling, async architectures provide limited benefits - the system still bottlenecks on synchronization points.
